
มาทำ Web Scraping อย่างง่ายด้วย cheerio กันเถอะ!
- Published on
- •4 mins read
สวัสดีครับ ในสัปดาห์นี้เราจะมาสอนทำ Web Scraping กันโดยใช้ library ที่ชื่อว่า cheerio กันนะครับ
Web Scraping เป็นการดึงข้อมูลดิบๆ ทางทางเว็บไซต์เพื่อเอาตัวแปร หรือค่าต่างๆ เอาไปประมวลผลต่อไป
งั้นเราก็มาเริ่มต้นการทำ Web Scraping กันเลยดีกว่า
เราจะใช้ HTML อันนี้เป็นตัวอย่างการเขียน Web Scraping สมมุติว่าหน้านี้อยู่ใน https://example.com/
<html>
<head>
<title>Awesome Title</title>
</head>
<body>
<div id="contentPrint">
<div class="row">
<div class="title">First Row</div>
<div class="data">Data 1-1</div>
<div class="data">Data 1-2</div>
</div>
<div class="row">
<div class="title">Second Row</div>
<div class="data">Data 2-1</div>
<div class="data">Data 2-2</div>
</div>
</div>
<a id="blog" href="https://blog.rayriffy.com/">Awesome Blog Link</a>
</body>
</html>เราก็จะมาเริ่มเขียนกันเลย
ขั้นตอนที่ 1: ติดตั้ง Dependencies ให้พร้อม
การติดตั้งก็ง่ายมาก แค่ใช้ npm หรือ yarn ในการติดตั้ง dependencies
ก็เริ่มจากลง cheerio ก่อน
$ yarn add cheerioแล้วเราจะรับ raw HTML มาจาก request-promise
$ yarn add request-promiseขั้นตอนที่ 2: โค๊ดแม่ง
คราวนี้ใน src/index.js ของเราก็จะ import และ intitialize dependency
คำเตือน! อันนี้เราจะเขียนใน ES6 ต้องเอาโค๊ดไป compile เป็น JS ก่อนถึงจะใช้งานได้ (แนะนำให้ใช้ backpack-core)
import cheerio from 'cheerio'
import rp from 'request-promise'เราก็จะเริ่มโดยการใช้ request-promise ฝนการไปดึง data มากจากเว็บก่อน
import cheerio from 'cheerio'
import rp from 'request-promise'
rp({
uri: `https://example.com/`,
transform: body => {
return cheerio.load(body)
},
})
.then($ => {
console.log($)
})
.catch(e => {
console.error(e)
})Pause แค่นี้ก่อนเรามาอธิบายโค๊ดส่วนนี้สักนิสนึง
rp({
uri: `https://example.com/`,
transform: body => {
return cheerio.load(body)
},
})โค๊ดนี้เราบอกว่าให้ไปดึงข้อมูลมากจาก https://example.com/ แล้วหลังจากดึงมากแล้วให้ transform โดยใช้ cheerio load ข้อมูลมา
.then($ => {
console.log($)
})
.catch(e => {
console.error(e)
})ถ้าหากรับข้อมูลผ่านก็จะเข้าไปที่ .then() แต่ถ้าไม่ผ่านก็จะวิ่งไป .catch()
แล้วเราก็จะมา Scraping ข้อมูลกันเลยดีกว่า!
เอาของง่ายๆ มากันก่อน เราจะดึงคำว่า First Row ยังไง? คำตอบคือเราจะต้อง Specify ด้วย Selector วิธีที่ง่ายที่สุดคือให้เราเปิด DevTools ขึ้นมาบนเว็บเลื่อนหา First Row แล้วคลิดขวาไปที่ Copy > Copy selector แล้วเราก็จะได้ Selector ออกมาแล้ว
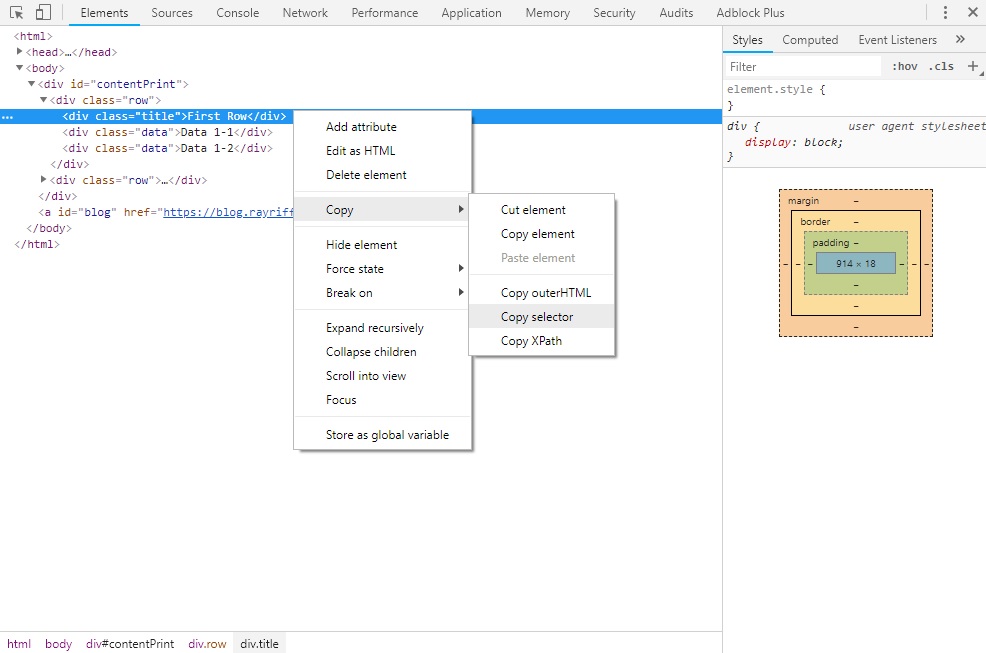
แล้วเราก็เอาไปใส่ cheerio แล้วบอกให้แสดง text ออกมา
import cheerio from 'cheerio'
import rp from 'request-promise'
rp({
uri: `https://news.sanook.com/lotto/`,
transform: body => {
return cheerio.load(body)
},
})
.then($ => {
console.log($('#contentPrint > div:nth-child(1) > div.title').text())
})
.catch(e => {
console.error(e)
})เราจะสามารถ Extract text ออกมาจาก Selector นั้นได้ด้วยการใช้ .text()
$('#contentPrint > div:nth-child(1) > div.title').text():nth-child(1) มีไว้เพื่อบอกว่าให้วิ่งเข้าไปที่ div อันแรก ถ้าสังเกตดีๆ จะเห็นว่าในหน้าเว็ยเราก่อนที่จะเข้าไปที่ div.title นั้นมี div.row ที่เป็นชื่อซ้ำกันอยู่ เราถึงใช้ :nth-child(1) เพื่อบอกว่าให้วิ่งไปอันแรก
ง่ายๆคือ ถ้าเป็นเป็น :nth-child(2) มันก็จะวิ่งไปที่ Second Row แทน แต่ถ้าเอาออกไปเลยล่ะ!????? มันก็จะเข้าทั้งคู่เลย แล้วเก็บข้อมูลออกมาเป็น Array นั่นเอง!!!

เราก็เรียกออกมาได้ด้วยการ Loop
import cheerio from 'cheerio'
import rp from 'request-promise'
rp({
uri: `https://news.sanook.com/lotto/`,
transform: body => {
return cheerio.load(body)
},
})
.then($ => {
$('#contentPrint > div > div.title').each((i, elem) => {
console.log($(elem).text())
})
})
.catch(e => {
console.error(e)
})จากที่เห็น cheerio มี Function ที่ช่วยในการทำ Loop ให้แล้วโดยใช้ .each() แล้วจะมี parameter อยู่ 2 ตัว
iจะเป็นเลข Indexes เผื่อต้องการใช้elemจะเป็น Element ใน Loop นั้น
แล้วเราก็เอา elem ออกมา Extract text ออกมา
$(elem).text()ความรู้เพียงแค่นี้ก็สามารถเอาไปเขียน Web Scraping ได้จริงแล้ว แต่เดี๋ยวนะริฟฟี่! ใน a#blog มี href ด้วยอ่ะจะเอาออกมายังไง?
เราสามารถดึง HTML Attribute ต่างๆ ออกมาได้ด้วยการใช้ .attr()
import cheerio from 'cheerio'
import rp from 'request-promise'
rp({
uri: `https://news.sanook.com/lotto/`,
transform: body => {
return cheerio.load(body)
},
})
.then($ => {
console.log($('#blog').attr('href'))
})
.catch(e => {
console.error(e)
})ว่าจากตัวอย่างโค๊ดน่าจะเดาได้นะว่าเกิดอะไรขึ้น
สรุป
จากตัวอย่างแค่นี้ เราก็สามารถทำ Web Scraping ได้แล้ว ตัวอย่างโปรเจคของเราก็จะเป็น API ที่เอาไว้ตรวจหวย คือใช้ cheerio ไปดึงข้อมูลมาจาก sanook.com แล้วเอา data ประมวลผลออกมาเป็น JSON
ตัวอย่างที่ GitHub
แล้วคำแนะนำเพิ่มเติมคือ ถ้าอยากจะหรูหรามากกว่านี้แนะนำให้ลองไปดู Puppeteer แต่หลักๆ แล้วแค่นี้ก็ทำได้เพียงพอแล้ว ก็หวังว่าจะได้ความรู้อะไรกลับไปบ้างนะครับ 555 ขอบคุณที่อ่านมาถึงจุดนี้ครับ แล้วเจอกันอีกทีสัปดาห์หน้า!
